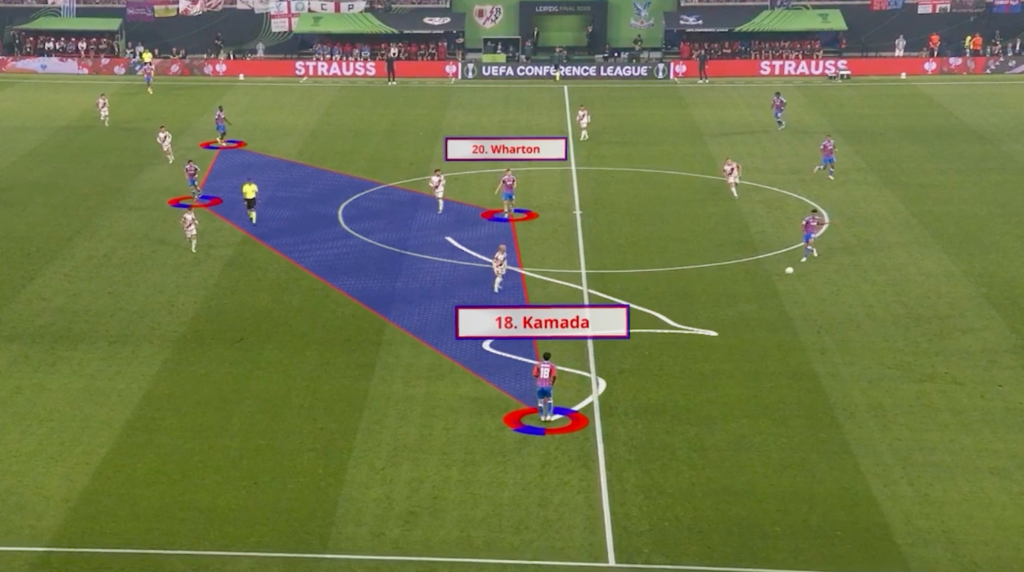
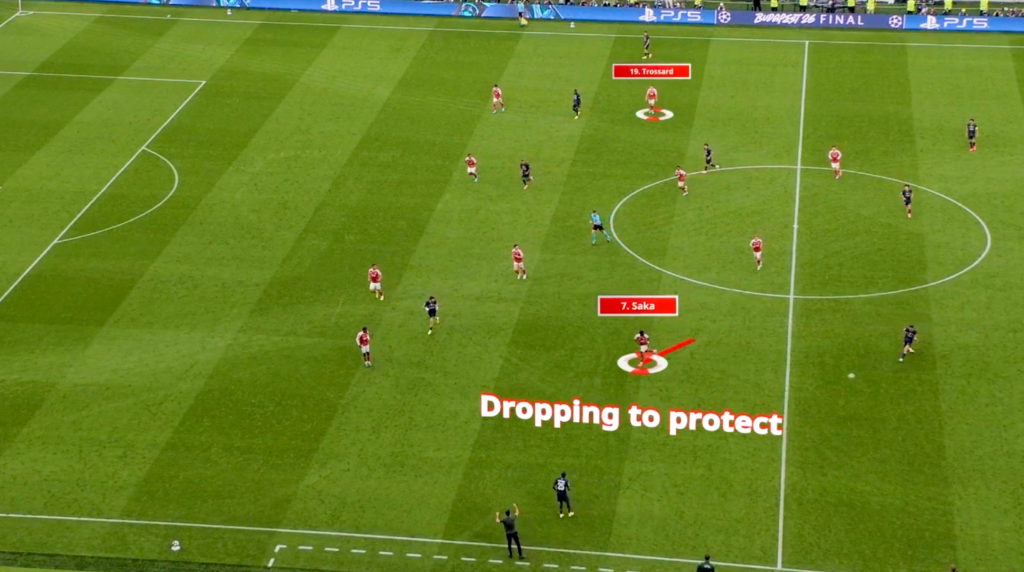
Når analytikerne skal forberede landsholdene på den kommende modstander, segmenterer analytikerne ud fra en manuel metode taktisk filmning af op til 10 kampe. Formålet er at segmentere den kommende modstander i spilfaser.
”Landsholdene” er i denne sammenhæng de danske hold, som har ressourcerne – det vil sige Herrelandsholdet, Kvindelandsholdet og U21-herrelandsholdet.
Segmenteringen er fundamentet for modstanderanalysen, som 1) beskriver modstanderens spillestil, 2) påvirker træningsplanlægning, trup- og holdsammensætning og 3) i sidste ende, hvilken plan der lægges for kampen.
Den manuelle annotering (tagging) er omstændig og repetitiv, og derfor et oplagt område at automatisere. I specialet Temporal Localization of Group Activities in Football Videos præsenterer Jakob Fahl en løsning til effektivt at lokalisere og klassificere ni spilfaser.
Løsningen består af to modeller: En videoklassifikationsmodel og en transformerbaseret model. Til sammen finder modellerne ni spilfaser på en brøkdel af den tid, det tager analytikeren.
Nedenfor kan du læse et resumé af specialet, og her kan du læse hele rapporten.
Analysen af modstanderen
Specialet undersøger automatiseringen af den manuelle tagging af spilfaser, som landsholdenes analytikere udfører i forberedelsen af landskampe. Kortlægningen af modstanderholdets strategier i de forskellige faser af spillet er altafgørende for, at trænerstaben sammen med analytikeren kan fastlægge, hvordan kampen skal gribes an.
Analytikeren kan dog først analysere modstanderholdets strategier, når analytikeren har tagget tilstrækkeligt videomateriale. Og det er lige præcis her, at en automatiseret løsning er ideel, idet spilfaserne er let genkendelige.
Data til træning og evaluering af førnævnte totrinsmodel blev leveret af Dansk Boldspil-Union (DBU) og består af taktisk filmning af herrelandsholdskampe og dertilhørende XML-filer med de manuelle annoteringer (tags). Eksempler på tags, kan du læse mere om i næste afsnit.
I præprocesseringen af datasættet blev det blandt andet besluttet, at ikke alle de tags, der opstod i den manuelle annotation, som skulle læres af modellen. Der blev derfor udvalgt følgende faser og deres spejlinger: Opbygning/højt pres (fase 1 VI/DE), kontrol/forsvarsspil (fase 2 VI/DE), gennembrud/forsvar feltet (fase 3 VI/DE) og omstillingsfaserne (VI-DE og DE-VI) og afslutningsvis tilføjet en niende fase “none”, som markerede alle tidspunkter i kampene, hvor ingen af de ovenstående otte faser var aktive (for eksempel når bolden var ude af spil).
Herfra blev kampene opdelt i klip af otte sekunder, og hvert af disse klip mærket med én af de ni spilfaser (afhængigt af de manuelle annotationer).
En effektiv og nøjagtig totrinsmodel
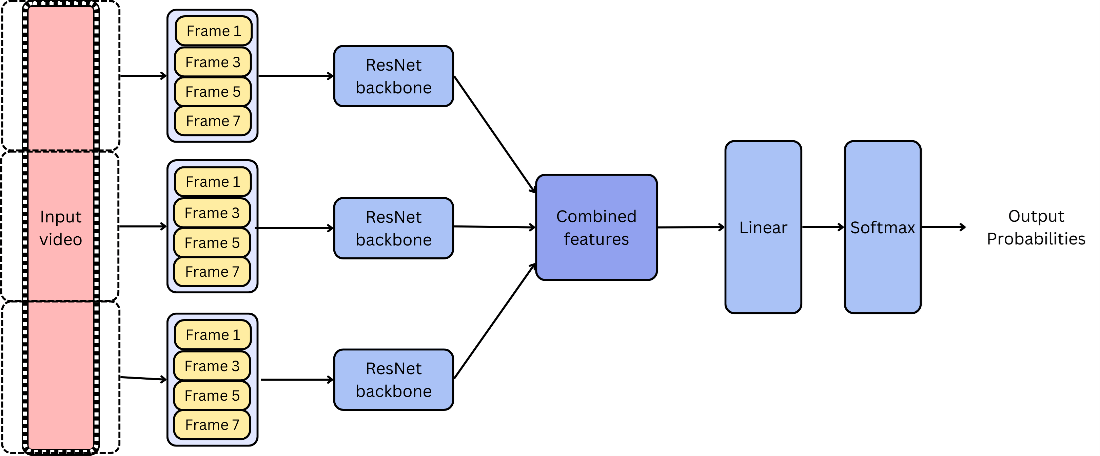
Videoklassifikationsmodellen, som er det første trin i den samlede løsning, er baseret på Temporal Segment Networks (TSN) (Wang et al., 2016).
TSN-modellen opererer ved at tage udvalgte frysbilleder (frames) fra de otte sekunder lange klip og kan ud fra frysbillederne forudsige, i hvilken spilfase klippet er. Modellens forudsigelser er en sandsynlighedsfordeling, som strækker sig over hver af de ni spilfaser.
Det vil altså sige, at modellen rapporterer en sandsynlighed for, at et givent klip tilhører hver af de ni faser. Hvis modellen for eksempel er meget sikker på, at et klip viser et opbygningsspil for et hold, der spiller fra venstre mod højre, vil modellen rapportere en sandsynlighed tæt på 100 procent for denne fase og tæt på 0 procent for resten. De ni fasers sandsynlighed vil altid til sammen give 100 procent.
Specialet viser, at TSN-modellen er forholdsvis præcis. På et tilfældigt udvalgt datasæt af klip opnåede modellen en nøjagtighed på 75 procent. Det betyder, at modellen ramte rigtigt tre ud af fire gange, når den fik et tilfældigt klip at se.
Dette var dog ikke generelt for hele testsættet, hvor præcisionen faldt til 67,52 procent. I tilfælde, hvor modellen ikke ramte rigtigt, viste det sig, at dens andet bud (spilfasen med næststørst sandsynlighed) ofte var korrekt. Når man tog de to mest sandsynlige gæt fra modellen, ramte den rigtigt i 84,38 procent af tilfældene.
Når man udvider til de tre mest sandsynlige gæt, steg præcisionen til 91,98 procent. Dette tyder på, at selvom modellen ikke altid vælger den mest sandsynlige klasse, er dens forudsigelser stadig meget pålidelige og informative.
Andet trin i modellen er en transformerarkitektur (Vaswani et al., 2017). Denne model tager en sekvens af resultater fra videoklassifikationsmodellen på 11 fortløbende klip og returnerer sandsynlighederne for hver af de ni spilfaser for det midterste klip (sjette klip af de 11 fortløbende).
Idéen her er, at modellen kan udnytte information om spilfaserne før og efter det udvalgte klip, og dermed opnå en større præcision. Tilføjelsen af dette trin forbedredede nøjagtigheden med 7,64 procent.
Samlet set demonstrerer specialet en effektiv og nøjagtig metode til automatisk identifikation af spilfaser i fodboldkampe ved hjælp af avancerede maskinlæringsmodeller.
Ved at reducere analytikerens manuelle arbejdsbyrde og forbedre præcisionen i faseidentifikationen kan denne tilgang være af stor værdi for landsholdenes forberedelser af landskampe.
Hvordan blev totrinsmodellen udviklet?
I dette afsnit kan du læse om de anvendte metoder og den tekniske tilgang, som specialet bygger på.
Først blev der taget en række metodologiske overvejelser i betragtning – herunder opdeling af spillet i mindre klip, valg af kliplængde og erkendelsen af, at kun én fase er aktiv ad gangen. Disse overvejelser dannede grundlaget for udviklingen af den samlede model bestående af videoklassifikationsmodel og transformerbaseret model.
Trin 1: Videoklassifikationsmodel
Videoklassifikationsmodellen, som er baseret på Temporal Segment Networks (TSN) (Wang et al., 2016), blev valgt som den første fase af den samlede model. Modellen bruger inputvideoer, der hver især er otte sekunder lange. Dette kræver, at hele fodboldkampen opdeles i mindre klip, som derefter behandles individuelt af modellen.
TSN-modellen fungerer ved at opdele de otte-sekunder lange inputvideoer i segmenter og derefter trække relevante træk ud fra hver segment for at forstå det overordnede indhold. Segmenter udvælges jævnt over hele videoen, hvilket sikrer, at både begyndelsen, midten og slutningen af videoen repræsenteres.
Inden for hvert segment udvindes træk ved hjælp af en ResNet backbone (He et al., 2015). Det er en dyb konvolutionel neural netværksarkitektur, der er kendt for sin evne til at træne dybere netværk ved hjælp af skip connections eller “shortcuts”.
Disse træk repræsenterer vigtige, visuelle egenskaber ved det specifikke segment. Til sidst kombineres disse træk fra alle segmenter i videoen og bruges derefter som input til en softmax-klassifikator, der bestemmer, hvilken splifase der finder sted i det pågældende segment.
Den komplette TSN videoklassifikationsmodel kan ses i figur 1.
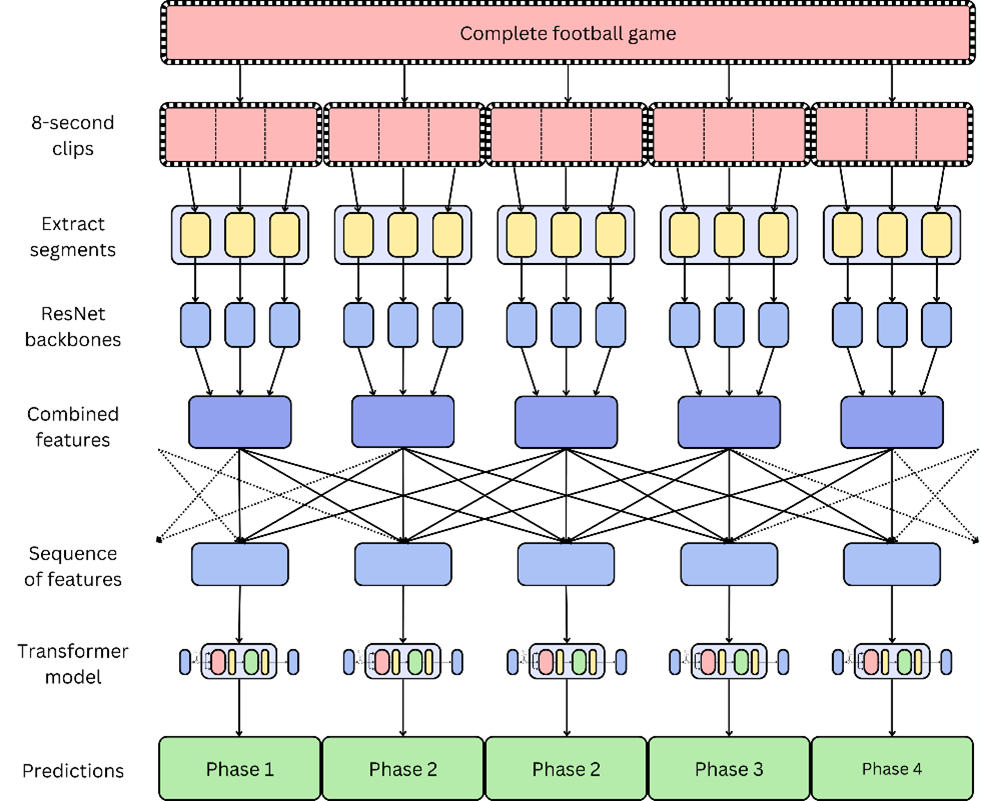
For at udnytte mere information fra videosekvenserne og opnå en dybere forståelse af det temporale forløb, blev sekvenserne af de udvundne træk brugt som input til den efterfølgende transformerbaserede model (se næste afsnit).
Sekvenserne bestod af udvundne træk fra 11 fortløbende otte-sekunders klip. I praksis betyder det, at transformermodellen forudsiger spilfasen af det midterste klip med information fra 40 sekunder før og 40 sekunder efter klippet.
Trin 2: Transformerbaseret model
Den transformerbaserede models arkitektur kan ses i figur 2. Den er inspireret af den originale transformerarkitektur (Vaswani et al., 2017), men med nogle ændringer. Den indeholder ikke en dekoder, da outputtet ikke er sekventielt.
Modellen består af:
- Inputprojektion: Inputprojektionen er et lineært feed forward-lag, der projekterer de 2048-dimensionelle træk ned på et 64-dimensionalt lag, hvilket er dimensionen af encoder-inputtet. Det vil sige at hver enkelt frysbillede fra den taktiske filming først bliver repræsenteret af 2048 tal, før projektionen formindsker den række af tal til 64. Denne transformation anvendes på alle trækkene i sekvensen, hvilket konverterer dimensionerne fra [11, 2048] til [11, 64].I bund og grund mapper den inputtræk til et lavere-dimensionelt rum, som modellen kan arbejde mere effektivt med.
- Positionel kodning: Den positionelle kodning tilføjer positionel information til sættene af træk. Det sikrer, at modellen kan adskille træk fra forskellige positioner i sekvensen, hvilket hjælper med at fange tidsmæssige afhængigheder. Det implementeres med en kombination af sinus- og cosinusfunktioner med forskellige frekvenser.
- Transformer encoder-lag: Modellen har N encoder-lag, hvor hvert lag indeholder multi-head attention, et feed-forward-netværk og lag-normalisering. Multi-head attention tillader modellen at fokusere på forskellige aspekter af inputtet på én gang ved at beregne vægtede summer af forskellige “head”-outputs. Dette gør det muligt for modellen at identificere vigtige sammenhænge og mønstre i data, hvilket er afgørende for effektiv sekvensmodellering og forståelse af kontekstuelle relationer.
- Feed-Forward Lag: Dette sidste lag tager encoder-outputtet af kun det midterste klip. Dette skyldes, at det er klippet, som modellen forsøger at forudsige mærket på, og information fra de foregående og efterfølgende klip læres i encoder-lagene. Encoder-outputtet mapper dette encoder-output til et ni-dimensionalt lag, efterfulgt af en softmax-aktiveringsfunktion til klassifikation.
Den samlede model
Ved at kombinere disse to trin opnås den samlede model, hvis arkitektur er illustreret i figur 3.
Dette er den endelige model, som analytikere kan bruge til at tagge fodboldkampe. For at få tagget en kamp af modellen skal analytikeren uploade en komplet taktisk filmning, hvilket er en optagelse af en hel kamp filmet med ét enkelt kamera.
Modellen vil derefter udføre de følgende trin:
- Den komplette filmning bliver delt op i sammenhængende otte-sekunders klip.
- Hvert af disse klip klassificeres gennem videoklassifikationsmodellen, som beskrevet tidligere.
- Trækkene fra disse klip ekstraheres og kombineres til sekvenser. Alle mulige sekvenser, der er 11 klip lange og dannet af fortløbende klip, oprettes. Det vil sige, at der bliver dannet en 11 klip lang sekvens med klip 1 til 11, en med klip 2 til 12, en med klip 3 til 13 og så videre.
- Disse sekvenser af træk sendes til den transformerbaserede model, som forudsiger spilfasen af det midterste klip i sekvensen. I sekvensen med klip 1 til 11 er det midterste klip således klip seks.
- Når alle sekvenser har været igennem den transformerbaserede model, så har modellen forudsagt spilfaserne for alle klip. Når disse kombineres, har modellen spilfaserne gennem hele kampen.
- Til sidst samles spilfaserne gennem hele kampen, og modellen returnerer en tagging af kampen i form af en XML-fil, som analytikeren kan bruge til at analysere modstanderen.
Referencer:
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, Ł. & Polosukhin, I. (2017). Attention is all you need. Advances in Neural Information Processing Systems (pp. 5998–6008).
He, K., Zhang, X., Ren, S. & Sun, J. (2015). Deep Residual Learning for Image Recognition (cite arxiv:1512.03385Comment: Tech report).
Wang, L., Xiong, Y., Wang, Z., Qiao, Y., Lin, D., Tang, X. & Gool, L. V. (2016). Temporal Segment Networks: Towards Good Practices for Deep Action Recognition. CoRR, abs/1608.00859.